
Please find a PDF with notes to the lecture and exercises here.
Open RStudio in the Browser (http://YOUR_PUBLIC_DNS:8787).
In RStudio, set the working directory to:
/home/ubuntu/wpsg_2016/activities/introgression_admixture_models
and open the commands_buerkle.R file. It contains commands that we will use and modify in some of these exercises.
Section 3.2 — #4
- Go to the code for this section in the commands_buerkle.R file.
- Run this code block and examine the plots for initial allele frequency of 0.5 and Fst of 0.4 and 0.1.
- Modify the preceding code block to consider an initial allele frequency of 0.1 instead, but with Fst of 0.4 and 0.4.
- Discuss in small groups: To what extent does drift (Fst) affect allele frequencies? How much does this depend on the starting allele frequency? What is the practical consequence for analysis?
Section 3.3 — #7
- Discuss in small groups: How realistic is it to assume all populations share a locus-specific Fst?
- Discuss in small groups: The alternative is that all (or sets of, e.g., in a genomic window) loci share an Fst, but that populations vary. How realistic and useful is that?
- Draw the part of the locus-specific model that we could modify as in the previous question, that would use sets of loci to learn about a population-specific Fst.
Section 4 — #2
- In the case of the no-admixture model (model repeated below), how could each component on the right side of the equation be distributed? Note, that each allele copy is considered separately, rather than in a genotype?
- Below is the equation for the posterior in the case of the admixture model. How could each component be distributed?
- The Pritchard et al 2000 structure admixture model assumes that all loci experience admixture (introgress) equally, i.e,
. Is this reasonable? How could we relax this assumption?

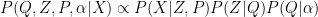
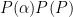
Section 5.2 — F-model simulation and Bayesian model to recover simulated values
Perform simulation and analysis of simulated data with Bayesian model that is written in JAGS. Follow along with the steps in the commands_buerkle.R file.
Daily questionnaire
Find the daily questionnaire for this exercise here.